
こんにちは。ecbeing金澤です。
普段はReviCoや他のプロダクトの開発リーダーをやりつつ、管理職としてチームのマネジメントもやったりしています。
1on1でついつい喋りすぎちゃう問題
プロダクト開発統括部では、個人の面談に1on1を取り入れています。
1on1はコーチングの場と言われており、基本的にはメンティー(部下)が喋り、メンター(上司)はその内容に対してフィードバックをする。
という流れが理想なのですが、自分が普段どのくらい喋っているかというのは、なかなか自分では分からないもの。
「見えない問題は解決できない」ので、どうにか可視化できないか考えていたところ
Amazon Transcribeを使えば計測できそう、ということに辿り着きました。
Amazon Transcribeとは
音声をテキストに変換してくれるAWSのサービスです。
https://aws.amazon.com/jp/transcribe/
最大10人までの声を聞き分けられるのですが、テキストと一緒に「○秒~○秒までは誰が喋った」というデータも出力してくれるので、
それを足し合わせたら、どちらが何%喋っているのか分かるのでは?と思いました。
(この記事ではそれを「会話ポゼッション」と呼ぶことにします)
実際にやってみる
1on1を録音する
試しに、同じチームのメンバーの宮原との1on1を録音してみることにしました。
普通にスマホアプリ等で録音すれば良いのですが、
Amazon Transcribeが対応しているフォーマットは
「MP3, MP4, WAV, FLAC, AMR, OGG, WebM」なのでご注意を。
(AACで録音しちまった…)
録音したファイルは、S3の適当な場所にアップしておきます。
Amazon Transcribeに食わせる
Amazon Transcribeのコンソールから「Create job」で新しいジョブを作ります。
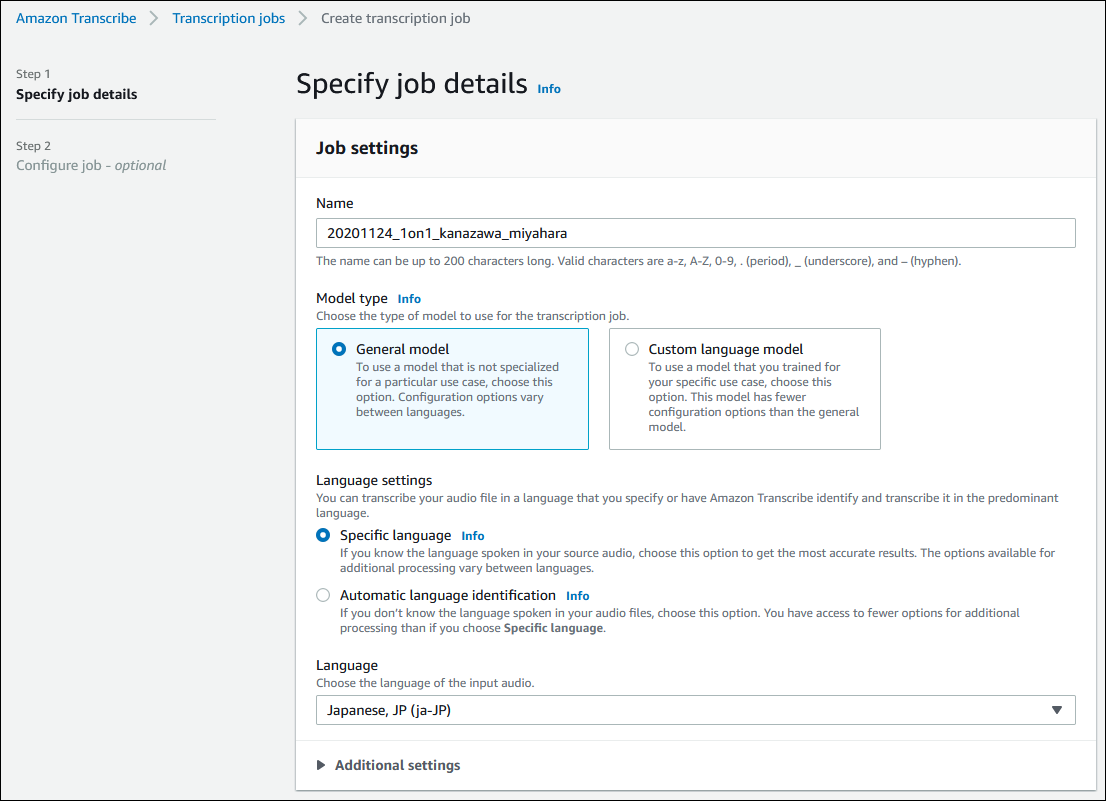
以下のように設定していきます。
| 項目名 | 説明 |
|---|---|
| Name | 適当に入れればOK |
| Model Type | General Model |
| Language settings | Specific language |
| Language | Japanese, JP (ja-JP) を選ぶ |
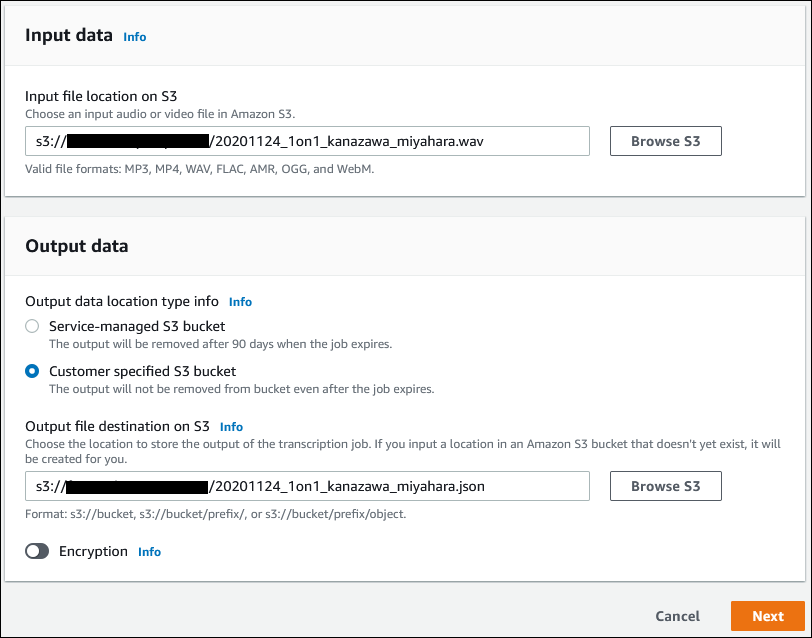
| 項目名 | 説明 |
|---|---|
| Input file location on S3 | 音声ファイルのパス |
| Output data location type info | 音声ファイルと同じ場所に出力したいので Customer specified S3 bucket を選ぶ |
| Output file destination S3 | S3のパス&出力ファイルの名前を指定する。拡張子は .json |
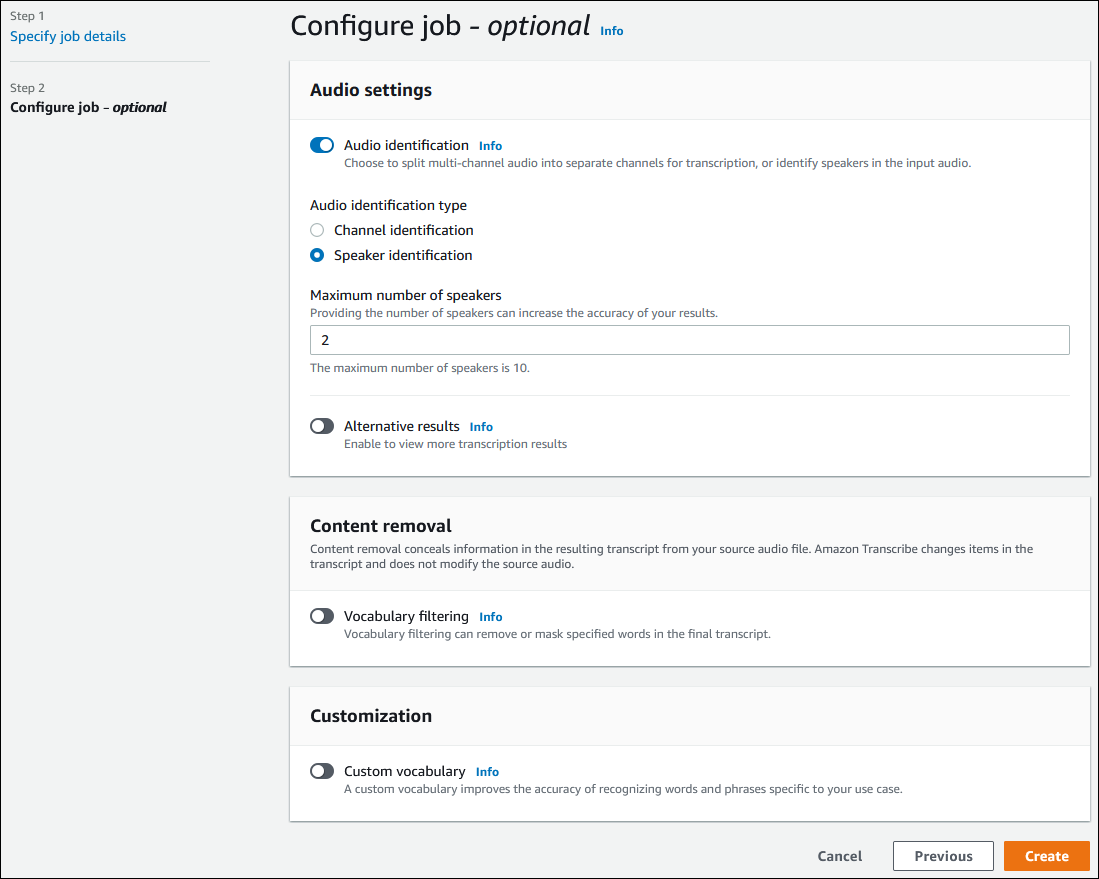
| 項目名 | 説明 |
|---|---|
| Audio identification | ONにする |
| Audio identification type | Speaker identification |
| Maximum numbers of speakers | 喋っている人数。2を入力する |
| それ以外 | 全部OFFでOK |
Createを押して、Completeになるまで待ちます。

S3にJSONファイルが出来上がっています。
結果のJSONを見てみる
JSONはこのような形で出力されます。
{ "jobName":"20201124_1on1_kanazawa_miyahara", "accountId":"************", "results":{ "transcripts": [ {"transcript":"音声のテキスト(省略)"} ], "speaker_labels":{ "speakers":2, "segments":[ { "start_time":"4.52", "speaker_label":"spk_1", "end_time":"7.07", "items":[ { "start_time":"4.52", "speaker_label":"spk_1", "end_time":"4.6" }, …(省略) ] }, …(省略) ] }, "items": [ …(省略) ], "status":"COMPLETED" }
この「speaker_labels->segments」のデータを使います。
発言者は spk_0、spk_1、…とラベリングされているので、speaker_label ごとに秒数を足し合わせていきます。
なお、誰にどのラベルが割り当てられたかは、実際に音声ファイルを聞きながら自分で判断することになります…。
(「seguments->items」の中に更にコマ切れになったデータが入っていますが、これは下部のitemsと紐付いていて、 Alternative results が格納されるみたい?です)
秒数を足し合わせていく
どうやっても良いんですが、まあこんな感じで…
<?php $json = json_decode(file_get_contents('20201124_1on1_kanazawa_miyahara.json')); $results = []; foreach ($json->results->speaker_labels->segments as $s) { $time = $s->end_time - $s->start_time; if (!isset($results[$s->speaker_label])) { $results[$s->speaker_label] = 0; } $results[$s->speaker_label] += $time; } var_dump($results);
結果
| 人 | 喋った時間 | 会話ポゼッション |
|---|---|---|
| 私(メンター) | 540.13秒 | 50.4% |
| 宮原(メンティー) | 531.32秒 | 49.6% |
(´-`).。oO(俺めっちゃ喋ってんなーーーーー)
ちなみに、プロダクト開発統括部のボスである渡邊と金澤の1on1も計ってみました。
| 人 | 喋った時間 | 会話ポゼッション |
|---|---|---|
| 渡邊(メンター) | 473.41秒 | 43.8% |
| 私(メンティー) | 608.45秒 | 56.2% |
渡邊はメンティーに自省を促すのが(少なくとも金澤よりは)上手く、
金澤は結構毎回べらべら喋っているので、もっと会話ポゼッションが低いと思っていましたが、案外そうでもありませんでした。
あと、1on1は毎回30分なのですが、どちらも1,800秒ある中で1,100秒くらいしかお互い喋っていないのは面白い傾向だなぁと思いました。
結論
メンティーの会話ポゼッションが高い=良い1on1だ、とは必ずしも言えませんが、
とりあえず次回はもっと聞き役に徹するのと、効果的な問いかけができるように準備して臨もうと思います。
「ヤフーの1on1」をもう1度読み直そう…。
~ecbeingでは、組織運営も一緒に試行錯誤してくれるメンバーを募集しています~
careers.ecbeing.tech