
Lightning Search内で使用されている技術、「Azure AI Search」に関する学習を行いましたので、今回はAzure AI Searchと言うサービスについて、学習したことや実際の実行結果を本ブログで共有します。
目次
- Azure AI Searchとは?
- Azure AI Searchについて紹介します。
- インデックスを作成する
- 検索に必要な「インデックス」を作成します。作成時の設定項目を紹介します。
- 文字列検索
- 形態素解析を用いた検索を行います。
- ベクトル検索
- 検索ワードとの類似度を計算して検索を行います。
- スキルセットについて
- スキルセットについて紹介します。
- 「感情分析」のスキル
- テキストからネガティブ・中立・ポジティブの判定を行います。
- 「言語解析」のスキル
- テキストの言語を判定します。
- 「キーフレーズの抽出」のスキル
- テキスト内の重要フレーズを抽出します。
- まとめ
- 本ブログのまとめです。
Azure AI Searchとは?

また、API機能を提供しているため、Webサイト・モバイルアプリなどで検索機能を簡単に実装することもできます。
インデックスを作成する
Azure AI Searchを使用して、高速な検索を行うには適切なインデックスを作成する必要があります。 インデックスはフィールド名、データ型、フィールド属性を設定して作成します。 データの整合性と検索精度を保つために、一度設定されたフィールド定義は後から変更することはできません。(一部除く)ここではインデックス作成時の設定値を見ていきましょう。

データ型
Azure AI Searchのインデックスでは様々なデータ型が選択可能です。選択可能なデータ型の例です。- String - テキストデータを格納
- Int32 - 32ビット整数を格納
- Int64 - 64ビット整数を格納
- Double - 浮動小数点数を格納
- Boolean - 真または偽の値を格納
- DateTimeOffset - 日付と日時の情報を格納
- SingleCollection - 浮動小数点数のリストを格納(ベクトルデータ格納に使用)
- 他
フィールド属性
フィールド属性では、フィールドごとの振る舞い(動き)を設定することができます。以下の設定項目があります。カッコ内の文字列はフィールド属性をSQLデータベースに例えてみました。- 取得可能 - 格納された値を取得(表示)可能にする (SELECT)
- フィルター可能 - 完全一致で絞り込みを可能にする (WHERE)
- 並べ替え可能 - 昇順や降順で並び替えを可能にする(ORDER BY)
- ファセット可能 - 検索ヒット数の表示を可能にする(COUNT)
- キー - データを識別するための一意の項目でインデックスに1つ必要(主キー)
- 検索可能 - 文字列検索 または ベクトル検索を可能にする
適切なインデックスを作成するメリット
- ストレージの節約
- 属性を適切に設定することで、必要以上のストレージ使用を防ぐことができます。「並び替え可能」や「フィルター可能」を選択するとAzure AI Searchは追加でインデックスし、より多くのストレージを使用してしまいます。そのため、必要なフィールドのみに属性を指定することでストレージの節約に繋がります。
- セキュリティの向上
- 「取得可能」をFalseに「検索可能」をTrueにすることで、「検索には使用するが、元データは出力したくないフィールド」を作成することも可能です。
文字列検索
ここからは文字列検索について紹介します。Azure AI Searchは検索対象がテキストの場合は形態素解析を行います。形態素解析では単語の分割や品詞の解析を行い、インデックスに登録します。その後、検索キーワードも同様に形態素解析を行い、インデックスのデータと照合を行います。インデックスの内容にマッチしたテキストを返却することで文字列検索を実現しています。
2種類の日本語アナライザー
テキストを形態素解析するには「アナライザー」を使用します。アナライザーはテキストデータを処理し、意味を理解しやすくするために用いられるツールや機能のことです。Azure AI Searchで使用可能な日本語のアナライザーには「ja.lucene」と「ja.microsoft」があります。それぞれの形態素解析の結果を比較してみましょう。入力テキストには当社のecパッケージの紹介文を使用します。
言語アナライザーを文字列フィールドに追加する - Azure AI Search | Microsoft Learn
| タイプ | 形態素解析結果 |
|---|---|
| 入力テキスト | ecbeingは、年商100億円のパソコンショップ「ソフトクリエイト」のオムニチャネル経験 から生まれたECサイト構築パッケージソフトです。実際のECビジネス経験とサイト運営者の立場で作られているため、使いやすく、充実した機能が満載。ecbeingはネットショップの新規開店やECサイトのリニューアルで、B2C/B2BによらずECサイト構築のさまざまな場面でご利用いただけます。 |
| ja.lucene (ルシーン) | Ecbeing/年商/1/0/0/億/円/パソコン/ショップ/ソフト/ソフトクリエイト/クリ/エイト/オムニチャネル/経験/生まれる/ec/サイト/構築/パッケージ/ソフト/実際/ec/ビジネス/経験/サイト/運営/者/立場/作る/使う/やすい/充実/機能/満載/ecbeing/ネット/ショップ /新規/開店/ec/サイト/リニューアル/b/2/c/b/2/b/よる/ec/サイト/構築/さまざま/場面/ご/利用/いただける |
| ja.microsoft | Ecbeing/年商/100億円/100億円/パソコン/ショップ/ソフト/クリエイト/クリェト/オムニチャネル/オムニチアネル/経験/から/生まれ/た/ec/サイト/構築/パッケージ/パッケジ/ソフト/です/実際/ec/ビジネス/経験/サイト/運営/者/立場/作ら/れ/て/いる/ため/使い/やすく/充実/し/た/機能/満載/ecbeing/ネット/ショップ/新規/開店/や/ec/サイト/リニューアル/リニュアル/b2c/b2b/よら/ず/ec/サイト/構築/さまざま/な/場面/ご/利用/いただけ/ます |
日本語アナライザー比較結果
- 1. 細かな分割の傾向
- ja.lucene アナライザーは、ja.microsoft アナライザーよりもテキストをより細かく分割していました。例えば、本文中の「B2C/B2B」というフレーズを見ると、ja.luceneは「b/2/c/b/2/b」として1文字ごとに細かく分割しているのに対し、ja.microsoftは「b2c/b2b」として単語毎に分割しています。
- 2. 数値の扱い
- ja.microsoft アナライザーは、数値に関しては半角と全角の両方のトークンを出力していました。例えば「100億円」という数値はja.microsoftでは「100億円/100億円」と2種類のトークンを出力しています。
- 3. 表記ゆれへの対応
- ja.microsoft アナライザーは、同じ単語を異なるトークンで出力することがありました。例えば、「オムニチャネル」はja.luceneではそのまま1トークンで出力していますが、ja.microsoftでは「オムニチャネル」と「オムニチアネル」の2つのトークンで出力しています。
- 4. 動詞の基本形への変換
- ja.lucene アナライザーは、動詞をその基本形に変換してトークンの出力を行っています。例えば、「作られている」と言う内容は「作る」と言うトークンで出力していました。
実際に文字列検索を試してみた
本ブログで公開されている記事のタイトルをインデックスに登録し、文字列検索を行いました。Azure AI Search上にインデックスを作成し、日本語アナライザーにはja.microsoftを選択しています。
ベクトル検索
ここからはベクトル検索について紹介します。ベクトル検索では検索対象のテキストを数値変換して、インデックスに登録を行います。検索キーワードも同様に数値変換を行い、インデックスに登録されたすべての数値との間で類似度を計算します。その後、類似度が高い順に結果を表示することにより、ベクトル検索を実現しています。
数値化の方法
Azure AI Searchにはテキストをベクトル化する機能は持っておらず、OpenAI社のEmbeddingと言う技術を使用します。変換の際に使用するモデルは複数用意されています。text-embedding-ada-002と言うモデルを使用することで、1536次元の数値が格納されている配列に変換することができます。 Azure AI SearchやOpenAI社のEmbeddingは従量課金制になります。そのため要件にあわせて、ベクトル化を行う際のテキストに何を含めるのが最適か検証していく必要があります。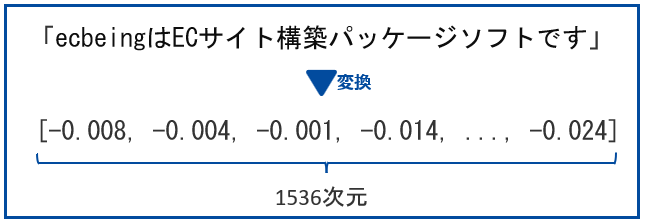
実際に検索を試してみた
本ブログで公開されている記事のタイトルのベクトル変換した値をインデックスに登録し、ベクトル検索を行ってみました。Azure AI Search上にインデックスを作成し、数値化にはモデルtext-embedding-ada-002を使用しています。検索結果には「新卒」というキーワードに対して、「新人」というワードが含まれているタイトルがあります。これにより、検索キーワードが直接含まれていないブログタイトルも検索結果に表示されるようになりました。
検索結果に終わりがありません
当社のブログにはBBQに関する記事は1つしか存在しません。「BBQ」と言うキーワードを使用して、文字列検索とベクトル検索をしてみました。画像はそれぞれの検索結果です。文字列検索ではBBQに関係しないブログ記事はヒットしませんが、ベクトル検索では検索キーワードに関係しないブログ記事も出力されてしまいます。ベクトル検索を使用する時は K-Nearest Neighbor Count を指定することで、取得する件数を制限することができます。
スキルセットについて

「スキルセット」は複数のスキルを組み合わせたものです。インデックス作成時にインデクサーがスキルセットを使用して、インデックスを作成することができます。これにより、スキルセットが出力した内容はインデックスに追加して検索に使用することができます。
「感情分析」のスキル
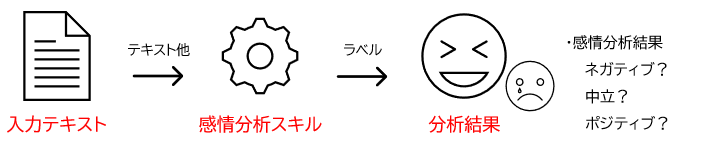
実際に「感情分析」のスキルを使用してみた
本ブログで公開されている記事のタイトルを使用して、感情分析のスキルを実行しました。インデックスに登録後、インデックスへの登録内容を出力しています。 "Sentiment"は感情分析のスキルが出力した内容になります。ブログタイトルの分析を通して、ネガティブ、ナチュラル、ポジティブのいずれかに分類されていることがわかります。「できなくなりました」や「難しい?」など、問題に直面している内容はネガティブと判断され、「イイネ!」や「素晴らしい」など技術的な成果や便利ツールの紹介はポジティブと判断されていました。
「言語解析」のスキル
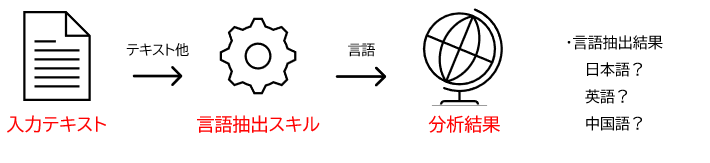
実際に「言語解析」のスキルを使用してみた
ecbeingの説明文をgoogle翻訳でさまざまな言語に変換後、言語解析のスキルを実行しました。インデックスに登録後、インデックスへの登録内容を出力しています。 "Answer"はGoogle翻訳を使用する際に選択した言語で、"SkillOutLang"は言語解析のスキルが出力した内容になります。私がGoogle翻訳で選択した言語と、スキルが出力した言語は同じ内容であることがわかります。
「キーフレーズの抽出」のスキル

実際に「キーフレーズの抽出」スキルを使用してみた
本ブログで公開されている記事のタイトルを使用して、キーフレーズ抽出のスキルを実行しました。インデックスに登録後、インデックスへの登録内容を出力しています。 "KeyPhrases"はキーフレーズの抽出スキルが出力した内容になります。ほとんどの文章で重要単語や文章の特徴を示すキーフレーズが抽出されていました。中にはキーフレーズは無しという結果もありました。「いまどき .NET Core 使ってないとやばくない?」というタイトルは個人的に「 .NET Core」が出力されると予想していましたが、違いました💦。
まとめ
本記事ではAzure AI Searchに関する、学習したことや実際の実行結果を共有しました。 Azure AI Searchを活用することにより、蓄積されたデータを基に、文字列検索やベクトル検索などを簡単に実装できることがわかりました。 さらに、豊富な設定オプションとスキルセットを用いたデータ加工を組み合わせることで、感情分析の結果を使用した絞り込みなど、多彩な検索手法を実現することもできました。ご覧いただきありがとうございました!